







Industrial reactors sit at the heart of modern manufacturing. From petrochemicals and specialty chemicals to pharmaceuticals, polymers, and energy systems, reactors are where raw materials are transformed into high-value products. Yet controlling these systems has always been a demanding challenge. Nonlinear reactions, strong variable coupling, time delays, disturbances, and strict safety limits make reactor control one of the most complex problems in engineering.
For decades, industry has relied on PID controllers and, more recently, Model Predictive Control (MPC) to maintain stable and efficient operation. While these methods are reliable and well understood, the growing demand for higher efficiency, tighter safety margins, and adaptive performance has opened the door to a new paradigm: Reinforcement Learning (RL) for real-time reactor control.
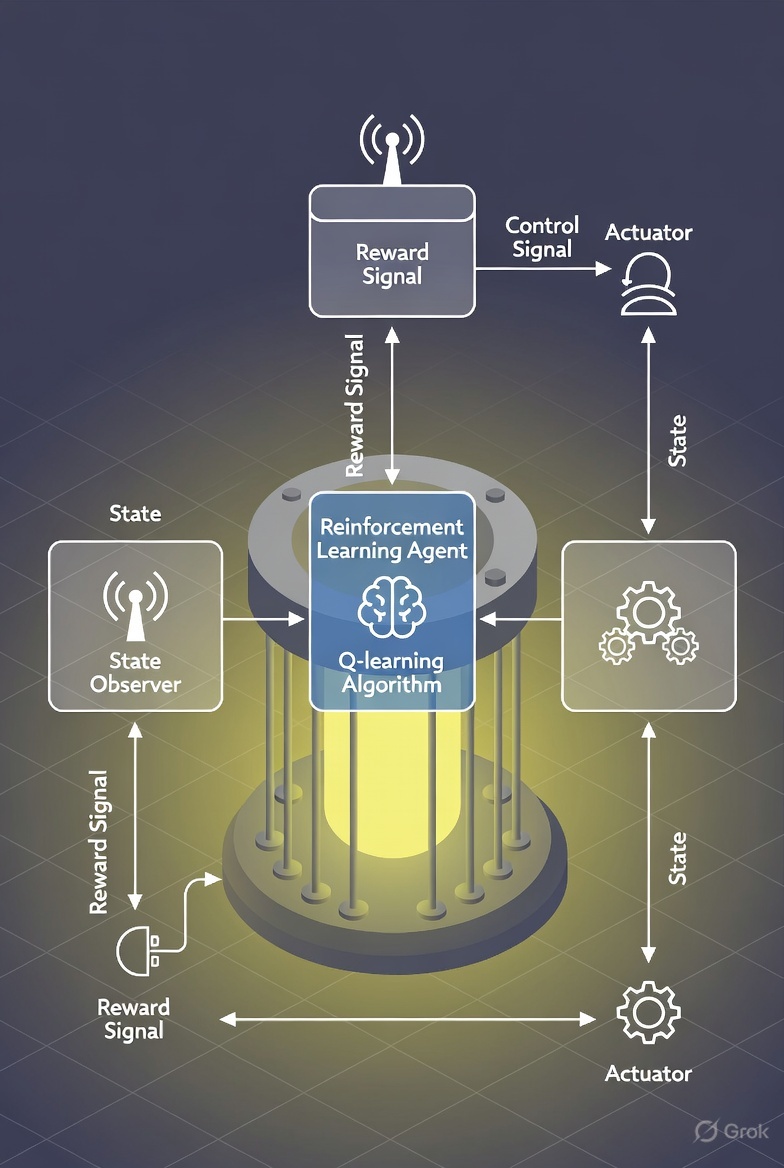
Reinforcement Learning, a branch of artificial intelligence, enables systems to learn optimal control strategies through interaction with their environment. Rather than depending entirely on predefined mathematical models, RL agents improve their behavior by maximizing a long-term reward signal. In reactor control, this means learning how to maintain temperature, pressure, and composition within desired ranges while optimizing yield and minimizing energy consumption.
Why Reactor Control Is So Challenging
Reactor systems are inherently nonlinear and multivariable. In an exothermic chemical reactor, for example, temperature influences reaction rate, and reaction rate feeds back into temperature. This positive feedback loop can lead to instability or thermal runaway if not properly controlled. At the same time, multiple inputs—such as coolant flow, feed rate, and heating power—affect several outputs simultaneously.
Additional complexities include:
Time-varying dynamics due to catalyst aging
Measurement noise and partial observability
External disturbances in feed composition
Hard safety constraints on temperature and pressure
Traditional PID controllers are simple and robust but struggle under large nonlinearities and constraints. MPC offers predictive optimization and constraint handling, but its performance depends heavily on model accuracy. When the model fails to capture real plant dynamics, performance degrades.
Reinforcement Learning offers a data-driven alternative capable of learning nonlinear control policies directly from interaction with a system or a high-fidelity simulation.
Formulating Reactor Control as a Learning Problem
Reinforcement Learning problems are typically modeled as Markov Decision Processes (MDPs). In this framework, the reactor becomes the environment, and the controller becomes the agent.
States
The state includes measurable and estimated process variables such as:
Reactor temperature
Pressure
Concentration of reactants and products
Flow rates
Coolant temperature
Reaction rates
In real plants, not all states are directly measurable. State observers or neural networks with memory (such as recurrent architectures) can infer hidden dynamics.
Actions
The agent manipulates control inputs, including:
Coolant flow rate
Feed rate
Heater power
Agitator speed
Control rod position (in nuclear systems)
Because these variables are continuous, reactor control requires continuous-action RL algorithms.
Reward Design
The reward function encodes operational goals. It typically penalizes deviations from setpoints, excessive energy use, and safety violations. A well-designed reward encourages stable, efficient, and safe operation.
Reward design is crucial. If safety penalties are too weak, the agent may learn aggressive but unsafe strategies. If economic objectives dominate, product quality may suffer. Balancing these objectives requires engineering insight.
Choosing the Right RL Algorithm
Continuous reactor control problems are well suited for modern deep RL algorithms such as:
Deep Deterministic Policy Gradient (DDPG)
Twin Delayed DDPG (TD3)
Soft Actor-Critic (SAC)
Proximal Policy Optimization (PPO)
Soft Actor-Critic has become particularly popular because of its stability and robust exploration behavior. It balances reward maximization with entropy, encouraging diverse exploration and avoiding premature convergence.
Model-free methods learn directly from data but can require large numbers of interactions. Since real reactors cannot tolerate risky experimentation, model-based RL is often preferred.
In model-based RL, a neural network learns the reactor’s dynamics. The controller uses this learned model to plan actions more efficiently, reducing the need for real-world trials.
Real-Time Constraints and Deployment
Industrial control systems operate under strict real-time constraints. Control actions must be computed within milliseconds. Therefore, trained neural networks must be lightweight and efficient enough for deployment on industrial hardware or edge devices.
Beyond computational speed, safety is paramount. Reactors must remain within strict operational limits. Exceeding temperature or pressure thresholds can lead to catastrophic failure.
To address this, several safety-enhancing strategies are used:
Constrained RL algorithms that explicitly limit unsafe behavior
Control Barrier Functions that mathematically enforce safety regions
Supervisory safety layers that override unsafe actions
Backup PID or MPC controllers as fail-safe mechanisms
These mechanisms ensure that even if the RL agent behaves unpredictably, the plant remains protected.
The Role of Digital Twins
Because exploration in real reactors is risky and expensive, RL training occurs in simulation. A digital twin—a high-fidelity virtual replica of the reactor—provides a safe training ground.
The digital twin incorporates nonlinear dynamics, disturbances, constraints, and realistic sensor noise. The RL agent interacts with this simulated environment, learning optimal policies over millions of virtual experiments.
After training, the agent is tested in shadow mode, where it observes real plant data and suggests actions without directly controlling the system. Only after extensive validation is gradual deployment considered.
Case Study: Continuous Stirred Tank Reactor
The Continuous Stirred Tank Reactor (CSTR) is a classic example used to evaluate advanced control strategies. In an exothermic CSTR, temperature and reaction rate are strongly coupled, making control difficult.
RL-based controllers trained on CSTR simulations have demonstrated:
Improved disturbance rejection
Faster startup transitions
Reduced overshoot
Enhanced economic optimization
Compared to traditional PID control, RL often performs better during large disturbances or nonlinear transitions. However, ensuring strict constraint adherence remains essential for industrial viability.
Hybrid Control: The Industrial Sweet Spot
One of the most promising approaches is hybrid control, combining RL and MPC.
In this architecture:
The RL agent optimizes long-term economic objectives and sets optimal operating targets.
The MPC controller ensures constraint satisfaction and stabilizes fast dynamics.
This layered strategy leverages the adaptability of RL and the reliability of MPC. It provides a practical path for industries that demand both innovation and safety.
Evaluating Performance
RL-based reactor controllers are evaluated using both control and economic metrics:
Integral of Squared Error (ISE)
Integral of Absolute Error (IAE)
Energy consumption
Product yield
Frequency of constraint violations
Robustness to disturbances
In modern process industries, economic and sustainability metrics are increasingly important. RL’s ability to optimize long-term objectives gives it a unique advantage.
Challenges and Future Directions
Despite its potential, RL for reactor control faces key challenges:
Improving sample efficiency
Providing formal stability guarantees
Achieving regulatory compliance
Enhancing interpretability
Emerging research areas include safe reinforcement learning, meta-learning for adaptive tuning, physics-informed neural networks, and multi-agent RL for distributed plants.
As computational power increases and digital twins become more accurate, RL is expected to play a larger role in intelligent process control systems.
Conclusion
Reinforcement Learning represents a transformative shift in how industrial reactors can be controlled. By learning nonlinear policies from data and simulation, RL offers the potential for adaptive, economically optimized, and highly efficient reactor operation.
However, real-world deployment requires rigorous safety mechanisms, hybrid architectures, and extensive validation. Rather than replacing classical control, RL is likely to complement it—enhancing performance while maintaining reliability.
As industries push toward smarter, more autonomous operations, intelligent reactor control powered by Reinforcement Learning may become a defining technology of next-generation process engineering.



